



Lab 1 MapReduce
!!! 这篇ai含量过高,找个时间按自己的理解再写一遍
MapReduce整体框架
主要组件
- Master节点:整个系统的协调者
- 任务分配与调度
- 状态监控与阶段管理
- 处理工作节点通信
- Worker节点:执行具体计算任务
- 执行Map任务:读取输入、处理数据、分区输出
- 执行Reduce任务:收集中间数据、排序、合并、输出结果
- 通信机制:基于RPC的Master-Worker交互
- 任务请求与分配
- 任务完成通知
- 健康检查
数据流
- 输入分片 → 2. Map处理 → 3. 分区/Shuffle → 4. 排序聚合 → 5. Reduce处理 → 6. 最终输出
MapReduce设计思路
核心设计原则
-
简化编程模型:
// 用户只需实现这两个函数 func Map(filename string, contents string) []KeyValue {...} func Reduce(key string, values []string) string {...} -
阶段性执行:
const ( MapPhase Phase = iota ReducePhase CompletePhase ) -
键值对处理:所有数据通过键值对表示和处理
-
确定性分区:
bucket := ihash(kv.Key) % task.NReduce intermediate[bucket] = append(intermediate[bucket], kv) -
自动并行化:Master将任务分配给多个Worker并行执行
-
容错机制:
// 任务超时检测 if m.mapTasks[i].Status == InProgress && time.Since(m.mapTasks[i].StartTime) > MapTaskTimeout { m.mapTasks[i].Status = Idle }
设计重难点
- 任务调度与负载均衡
- 如何合理分配任务给不同Worker
- 如何处理性能差异大的异构环境
- 容错机制设计
- 代码中使用了任务状态跟踪和超时重置机制
- 实现了临时文件+原子重命名确保中间结果可靠性
- Shuffle阶段效率
- 中间数据的传输和组织是整个系统的瓶颈
- 使用了基于哈希的分区策略和排序来优化
- 内存管理
- 处理大数据集时避免内存溢出
- 代码中使用了文件系统作为中间存储
- 一致性保证
- 确保即使在失败情况下也能得到正确结果
- 使用了原子写入和重复通知机制
关键实现技巧
-
阶段性状态管理:清晰划分MapPhase和ReducePhase
-
任务状态追踪:使用Idle/InProgress/Completed状态标记
-
原子文件操作
tempFile, err := ioutil.TempFile(".", "reduce-*") // ... 写入数据 ... os.Rename(tempFile.Name(), finalName) -
确定性哈希分区:保证相同key的数据到同一个reducer
5.监控与日志:记录任务执行情况和性能数据
Master中互斥锁的作用
互斥锁的作用
- 保护共享数据结构
- 保护
mapTasks和reduceTasks数组不被并发修改 - 保护计数器
completedMapTasks和completedReduceTasks - 保护阶段标识
phase的一致性
- 保护
- 确保操作原子性
- 任务分配过程必须是原子的
- 阶段转换必须是原子的(Map→Reduce→Complete)
- 状态更新必须是原子的(Idle→InProgress→Completed)
- 防止竞态条件
- 多个Worker同时请求任务
- 任务完成和任务超时检测同时发生
- 阶段判断和阶段转换同时发生
如果不加锁会发生什么
若不使用锁,将导致以下严重问题:
1. 任务重复分配
// 没有锁保护的任务分配
if m.mapTasks[i].Status == Idle {
m.mapTasks[i].Status = InProgress // 危险!
// 分配任务...
}问题:两个Worker几乎同时调用RequestTask,都会看到相同任务处于[Idle]状态,导致同一任务被分配给多个Worker。
2. 状态不一致
if m.completedMapTasks == m.nMap && m.phase == MapPhase {
m.phase = ReducePhase // 危险!
}问题:一个Worker增加completedMapTasks并检测阶段转换条件,同时另一个Worker也在做同样的事,可能导致阶段转换被执行两次,或者状态判断基于不一致的数据。
3. 计数错误
m.completedMapTasks++ // 危险!问题:多个Worker可能同时完成任务并增加计数器,没有锁保护会导致计数器值错误(经典的非原子递增问题)。
4. 超时判断与任务完成冲突
// 在checkTaskTimeouts中
if task.Status == InProgress && time.Since(task.StartTime) > Timeout {
task.Status = Idle // 危险!
}
// 同时在ReceiveFinishedMap中
task.Status = Completed // 危险!问题:背景线程可能正在将超时任务重置为[Idle](vscode-file://vscode-app/c:/Users/Radein/AppData/Local/Programs/Microsoft VS Code/resources/app/out/vs/code/electron-sandbox/workbench/workbench.html),同时Worker报告任务完成,导致完成的任务被错误地重置。
5. 死锁和活锁
不使用锁的系统容易进入死锁或活锁状态,例如:两个Worker都在等待对方释放的资源,或者系统在状态间无限震荡。
实例分析
func (*m* *Master) ReceiveFinishedMap(*args* *MapTaskCompleteArgs, *reply* *EmptyReply) *error* {
m.mutex.Lock()
defer m.mutex.Unlock()
taskId := args.TaskId
if m.mapTasks[taskId].Status != Completed {
m.mapTasks[taskId].Status = Completed
m.completedMapTasks++
// 如果所有Map任务完成,切换到Reduce阶段
if m.completedMapTasks == m.nMap && m.phase == MapPhase {
m.phase = ReducePhase
}
}
return nil
}
没有锁的情况下,多个Worker同时报告任务完成会导致completedMapTasks计数错误,进而导致阶段转换错误,最终系统可能永远无法完成或产生错误结果。
中间区域(Intermediate Regions)的深入分析
定义与作用
中间区域指Map阶段生成的键值对在传递给Reduce任务前的存储区域。具体特点如下:
-
分区存储
Map输出的中间数据按哈希分区函数划分为R个分区(R=Reduce任务数),每个分区对应一个Reduce任务。例如,当R=3时,Map输出的每个键通过hash(key) % R确定其分区:python
复制
def partition(key, R): return hash(key) % R -
本地化存储
中间数据默认存储在Map任务执行节点的本地磁盘(而非GFS),原因包括:- 减少网络开销:Reduce任务直接拉取本地数据,避免跨节点传输。
- 容错机制:若Map任务失败,重新执行后中间数据可快速重建。
-
数据组织
每个Map任务为每个Reduce分区生成一个中间文件(如mr-map-X-Y,X为Map任务ID,Y为分区号)。Reduce任务需从所有Map节点拉取对应分区的文件:复制
Map任务1 → 生成 mr-1-0, mr-1-1, mr-1-2(R=3) Map任务2 → 生成 mr-2-0, mr-2-1, mr-2-2 Reduce任务0 → 收集所有mr-*-0文件
关键作用
- 减少Shuffle带宽
中间数据本地存储避免了集中式存储的网络瓶颈。假设某Map任务输出10GB数据,若存储在本地,Reduce任务通过并行拉取各节点数据,而非从单一存储点下载。 - 容错与恢复
Map任务若失败,主节点重新调度该任务到其他节点,新生成的中间数据覆盖旧数据。Reduce任务仅处理已完成的Map任务输出,确保数据一致性。 - 排序优化
Map任务常对中间数据按键排序(如Hadoop的Sort阶段),使Reduce任务可直接归并排序后的文件,提升处理效率。
任务粒度(Task Granularity)的讨论
定义与权衡
任务粒度指单个Map或Reduce任务处理的数据量大小,直接影响系统的并行度和调度效率:
- 细粒度(更多小任务)
- 优点:
- 动态负载均衡:主节点可快速将小任务分配给空闲节点,避免“拖尾任务”(Straggler)问题。
例如:1000个Map任务(每个处理16MB数据)比100个任务(160MB/个)更易均衡分配到100个节点。 - 快速故障恢复:任务失败时仅需重算小量数据。
- 动态负载均衡:主节点可快速将小任务分配给空闲节点,避免“拖尾任务”(Straggler)问题。
- 缺点:
- 调度开销:管理数千任务需更多元数据(如任务状态、位置)。
- 启动延迟:频繁启停任务增加框架开销。
- 优点:
- 粗粒度(更少大任务)
- 优点:减少调度和任务管理开销。
- 缺点:易导致负载不均和恢复延迟。
MapReduce的设计选择
MapReduce采用 细粒度Map任务 和 粗粒度Reduce任务 的混合策略:
- Map任务细粒度化
- 输入文件被分割为多个小块(如64MB),每个块对应一个Map任务。
- 优势:
- 数据本地化:任务调度到存储输入块的节点,减少数据传输。
- 并行度最大化:大量Map任务可快速填充集群资源。
- Reduce任务适度粗粒度
- Reduce任务数R通常由用户指定(如等于集群节点数)。
- 原因:
- Reduce阶段需跨节点聚合数据,过多任务会增加Shuffle开销。
- Reduce输出写入GFS,较大文件更适合GFS的块存储策略(如64MB块)。
参数调优示例
- Map任务数M:通常远大于工作节点数(如M=1000,节点=100),以实现动态分配。
- Reduce任务数R:设为节点数的较小倍数(如R=50),平衡并行度与Shuffle成本。
总结
- 中间区域是MapReduce实现高效Shuffle和容错的核心设计,通过本地存储和分区策略优化数据传输。
- 任务粒度的平衡使MapReduce兼具高并行度与低管理开销,细粒度Map任务解决负载均衡,适度Reduce任务避免网络瓶颈。
MapReduce中的Shuffle机制解析
Shuffle机制的目的
Shuffle机制在MapReduce框架中的作用不仅仅是"分割大数据",而是要满足两个关键需求:
- 分组聚合:确保相同key的所有数据都被发送到同一个Reducer处理
- 负载均衡:尽量使数据均匀分布到各Reducer,避免数据倾斜
Shuffle实现
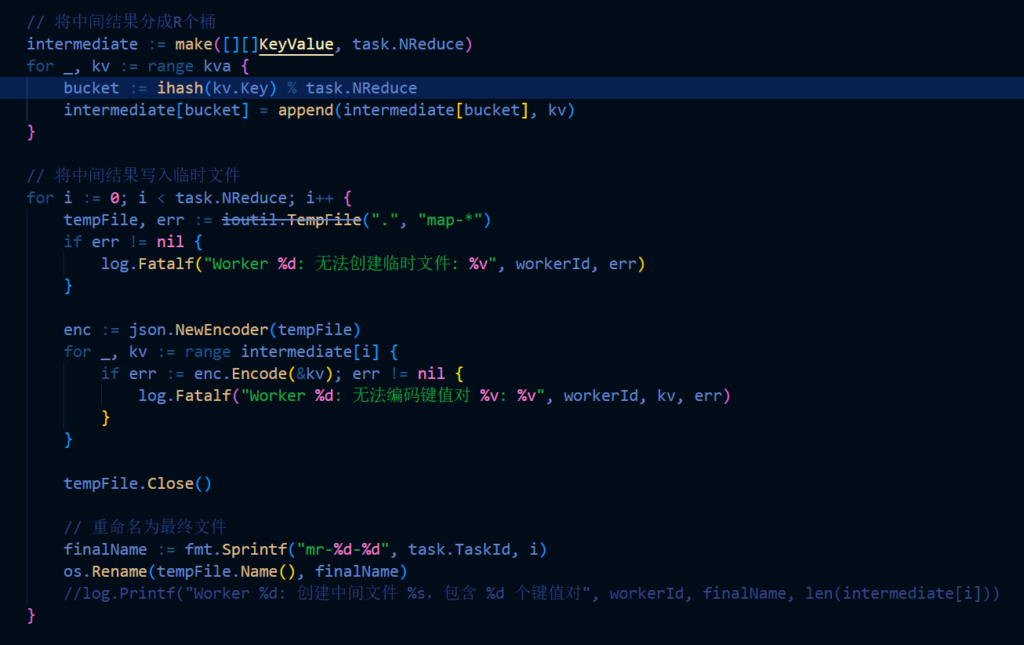
// Map阶段:决定每个键值对去向的哈希分区
intermediate := make([][]KeyValue, task.NReduce)
for _, kv := range kva {
bucket := ihash(kv.Key) % task.NReduce
intermediate[bucket] = append(intermediate[bucket], kv)
}
// Reduce阶段:收集后排序聚合的过程
sort.Sort(ByKey(intermediate))
// ...按key分组处理...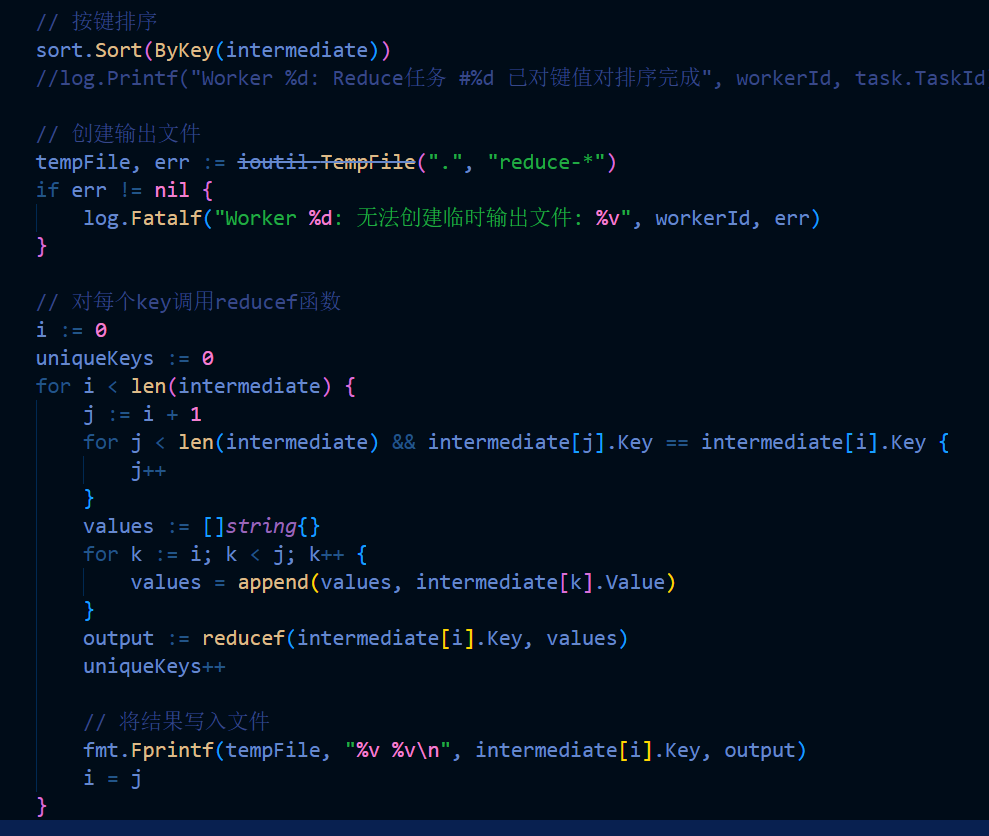
Shuffle的关键特性
- 哈希分区:通过哈希函数实现确定性分区,保证相同key一定去同一个Reducer
- 数据局部性:每个Map任务将结果写到本地,Reduce任务需要从多个Map任务拉取数据
- 均衡性:理想情况下应均匀分布,但实际上取决于数据特性和哈希函数质量
- 你的代码使用FNV-1a哈希后对nReduce取模,对随机键分布较均匀
- 但如果有热点key出现,仍可能导致数据倾斜
- 物理过程:不只是逻辑上分区,还包括实际的网络传输、磁盘IO

Comments | NOTHING